2.8 KiB
title, summary, date, authors, tags, excludeSearch, draft
| title | summary | date | authors | tags | excludeSearch | draft | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Petabytes of Internet Archive Data at the Tip of Your Fingers | If you know the bucket name that is 😄 | 2026-05-06T09:00:00-04:00 |
|
|
false | true |
We have added the internetarchive bucket to https://s3.labs.dataforcanada.org.
flowchart TD
Client(["🌐 S3 Client / User"])
Gateway["<b>s3.dataforcanada.org</b>\nS3-Compatible Gateway"]
Client -->|"S3 API Request"| Gateway
Gateway -->|"sourcecooperative bucket"| AWS
Gateway -->|"backblaze-ca-east-006 bucket"| BB
Gateway -->|"cloudflare-apac bucket"| CFAPAC
Gateway -->|"cloudflare-enam bucket"| CFENAM
Gateway -->|"internetarchive bucket"| INTERNETARCHIVE
Gateway -->|"tigris bucket"| TIGRIS
subgraph AWS ["☁️ Amazon Web Services"]
AWSNode["📍 Oregon, United States"]
end
subgraph BB ["🔵 Backblaze B2"]
BBNode["📍 Toronto, ON, Canada"]
end
subgraph CFAPAC ["🟠 Cloudflare R2"]
CFAPACNode["📍 Asia Pacific Region"]
end
subgraph CFENAM ["🟠 Cloudflare R2"]
CFENAMNode["📍 Eastern North America"]
end
subgraph INTERNETARCHIVE ["📚 Internet Archive Data"]
INTERNETARCHIVENode["📍San Francisco, United States and Vancouver, Canada"]
end
subgraph TIGRIS ["⚡ Tigris Data"]
TIGRISNode["11 Regions Worldwide 🌍\nAuto-routes to nearest location\nfor lowest latency"]
end
style Gateway fill:#1a5f7a,color:#fff,stroke:#0d3d52
style Client fill:#2d6a4f,color:#fff,stroke:#1b4332
style AWSNode fill:#ff9900,color:#000,stroke:#cc7a00
style BBNode fill:#e03c31,color:#fff,stroke:#b02d24
style CFAPACNode fill:#f6821f,color:#fff,stroke:#c4681a
style CFENAMNode fill:#f6821f,color:#fff,stroke:#c4681a
style TIGRISNode fill:#6c3483,color:#fff,stroke:#512e6b
Notes
-
Internet Archive S3 Documentation https://archive.org/developers/ias3.html
-
You need to know your identifier of your dataset (aka your bucket). For example, earth-at-night-2016
-
30 GB per 5 minute bandwidth quota as the Internet Archive has limited budget
-
Curious if anybody has made an index of all Internet Archive buckets
-
I believe it would be ideal to have an Internet Archive serverless worker(s) that are situated closer to the Internet Archive, then connect to those, as they do not have a CDN
-
And it looks like we're getting throttled, even with keys
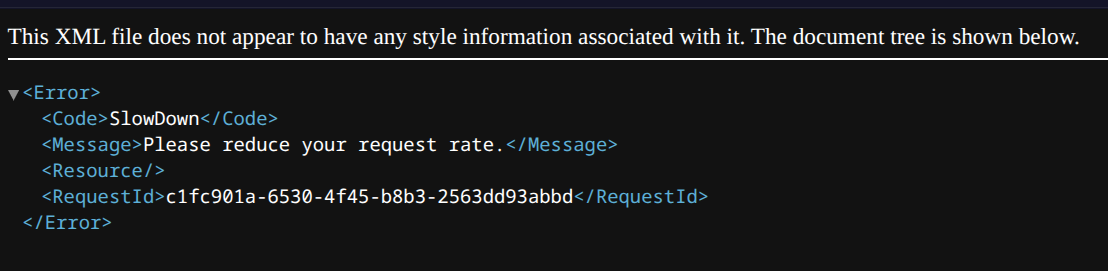
-
Due to IA's architecture, it might be necessary to map their /download, for example http://archive.org/download/region-of-peel-2021-orthoimagery/Peel_75mm_2021.tif to S3 operations

{kind=link}